The Iris Dataset contains four features (length and width of sepals and petals) of 50 samples of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). A sepal is the outer parts of the flower (often green and leaf-like) that enclose a developing bud. The petal are parts of a flower that are the pollen producing part of the flower that are often conspicuously colored. The difference between sepals and petals can be seen below.
The data were collected in 1936 at the Gaspé Peninsula, in Canada. The data set is prepackaged in R, and is called iris.
Last time, we conducted a hypothesis test to test for a difference between the mean sepal length of setosa and versicolor. Now, we want to estimate what the difference actually is.
First, we want to filter the data set to only contain our two Species. Please create a new data set that achieves this below. Let’s also calculate our statistic.
# A tibble: 2 × 2
Species mean_sep
<fct> <dbl>
1 setosa 5.01
2 versicolor 5.94
Based on the above calculation, our point estimate is:
\(\bar{x_s} - \bar{x_v}\) = -0.93
Now, let’s create our distribution in R:
Bootstrap Distributon
The term bootstrapping comes from the phrase “pulling oneself up by one’s bootstraps”, which is a metaphor for accomplishing an impossible task without any outside help
Impossible task: estimating a population parameter using data from only the given sample.
set.seed(12345)boot_df<-iris_filter|>specify(response =Sepal.Length, explanatory =Species)|>generate(reps =1000, type ="bootstrap")|>calculate(stat ="diff in means" , order =c("setosa", "versicolor"))
Dropping unused factor levels virginica from the supplied explanatory variable 'Species'.
Take a glimpse at boot_df. What do you see?
difference in resampled means
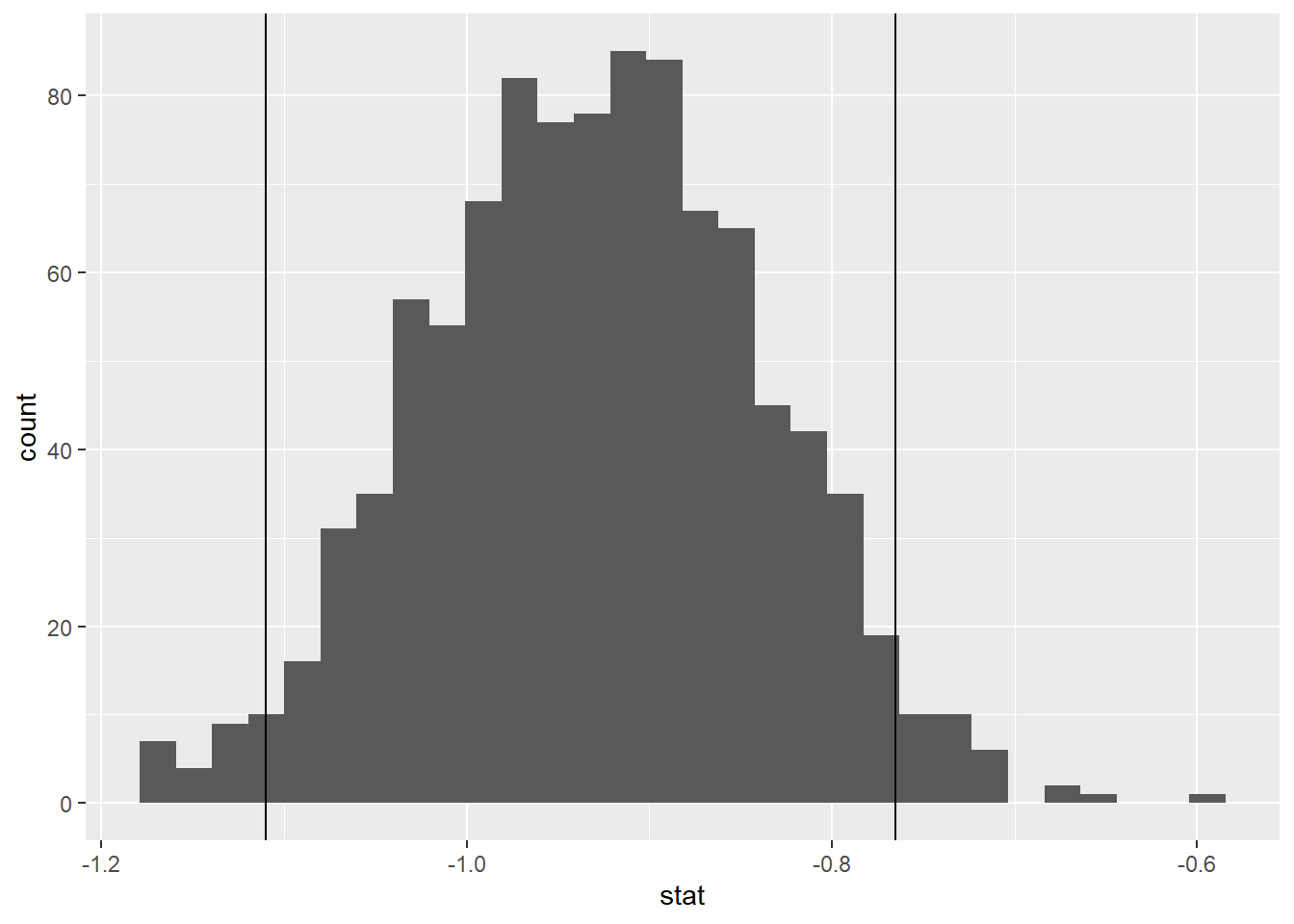
Plot a histogram of boot_df. Where is it centered? Why does this make sense?
Let’s visualize our confidence interval by adding a vertical line at each of these values. Use the code you wrote above and add two lines using geom_vline.
(see histogram above).
What is the correct interpretation of our calculated confidence interval?
We are 95% confident that the true mean sepal length for setosa is 0.765 to 1.11 units smaller than the true mean sepal length for versicolor.
Confidence intervals are often misinterpreted as probability….
Confidence is different than probability, as probability refers to an observed outcome of a random variable. Our population paramter is not a random variable. Confidence can be defined as: If we generate many confidence intervals under the same circumstances, we would expect roughly 95% of all confidence intervals to capture the population parameter.
Is 0 in our confidence interval?
No
Would we have expected 0 to be in our confidence interval based on our hypothesis test at a \(alpha\) = 0.05?
We would not! This is because we rejected the null hypothesis in the previous ae.
What happens if I go from a 95% confidence interval to a 90% confidence interval?
Gets more narrow
Review
For the following situations, practice:
Setting up the null and alternative hypothesis
Writing the proper notation for the sample statistic
Describing the simulation scheme for a hypothesis test
Describing the simulation scheme for a confidence interval
Situation 1
Cardiopulmonary resuscitation (CPR) is a procedure used on individuals suffering a heart attack when other emergency resources are unavailable. This procedure is helpful in providing some blood circulation to keep a person alive, but CPR chest compression can also cause internal injuries. Internal bleeding and other injuries that can result from CPR complicate additional treatment efforts. For instance, blood thinners may be used to help release a clot that is causing the heart attack once a patient arrives in the hospital. However, blood thinners negatively affect internal injuries.
Here we consider an experiment with patients who underwent CPR for a heart attack and were subsequently admitted to a hospital. Each patient was randomly assigned to either receive a blood thinner (treatment group) or not receive a blood thinner (control group). The outcome variable of interest was whether the patient died within the 24 hours. There were 50 individuals in the control group and 40 individuals in the treatment group.
\(H_o: \pi_t - \pi_c = 0\)
\(H_o: \pi_t - \pi_c > 0\)
Our statistic is: \(\hat{p_t} = \hat{p_c}\)
For a null distribution, we would randomly shuffle the data into one group, and permute the data back into two new groups of size 50 and 40. We would then calculate the proportion of those who died in each group and subtract the proportions.
For a bootstrap distribution, we would randomly sample with replacement from each group 50 and 40 times respectivly. Then, we would calculate new proportions for each group and subtract.
Situation 2
We have data on the price per guest (ppg) for a random sample of 50 Airbnb listings in 2020 for Asheville, NC. We are going to use these data to investigate what we would of expected to pay for an Airbnb in in Asheville, NC in June 2020. Today, we are going to investigate if the mean price of an Airbnb in Ashville, NC in June 2020 was larger than 60. Note: The value of your sample statistic is 76.6.
\(H_o: \mu = 60\)
\(H_a: \mu > 60\)
\(\bar{x} = 76.6\)
The null distribution scheme is slightly different for a single mean than for others. We need to make a null distribution centered at 60. Thus, we are going to shift our data by - 16.6, so that when we re sample with replacement 50 times, we get a simulated sample mean under the assumption that the mean is 60. Doing this 1000 times will give us a distribution centered at 60.
For confidence intervals, we resample with replacement 50 times, calculate the new resampled mean, and plot it.