Loading required package: airports
Loading required package: cherryblossom
Loading required package: usdata
Attaching package: 'openintro'
The following object is masked from 'package:modeldata':
ames
Bumba or Kiki
How well can humans distinguish one “Martian” letter from another? In today’s activity, we’ll find out. When shown the two Martian letters, kiki and bumba, answer the poll: https://app.sli.do/event/etoay5PwN5Mg5qiYg6BnDf/embed/polls/647dc94f-b22d-491d-b0ad-35552b27d01f
– Option 1: 75
– Option 2: 8
The question is: “Which letter is Bumba”?
Option 1
Once it’s revealed which option is correct, please write our sample statistic below:
\(\hat{p}\) = .904
Option 1
Let’s write out the null and alternative hypotheses below
Ho: \(\pi = 0.5\)
Ha: \(\pi > 0.5\)
Now, let’s quickly make a data frame of the data we just collected as a class. Replace the … with the number of correct and incorrect guesses.
Now let’s simulate our null distribution by filling in the blanks. First, detail how this distribution is created?
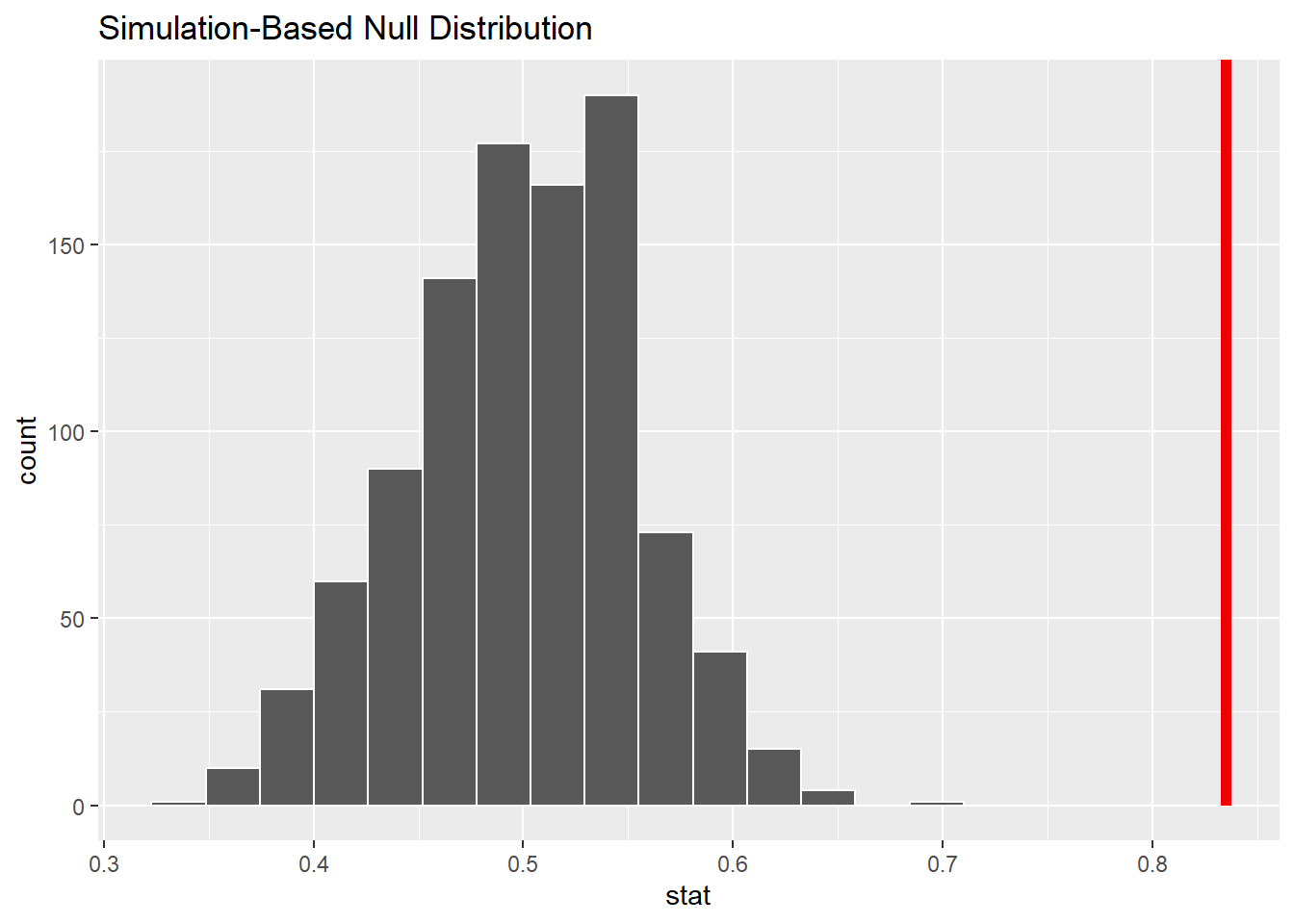
We can use a data generating mechanism, such as a spinner or a coin. We will use a spinner, with 50% “correct” and 50% “incorrect”. Then, we spin the spinner “n” number of times (83). Then, we take the proportion of correct guesses of the 83. This is one simulated observation. We do this process many many times to create a null distribution.
set.seed(333)null_dist<-class_data|>specify(response =correct_guess, success ="Correct")|>hypothesize(null ="point", p =.5)|>#fill in the blankgenerate(reps =1000, type ="draw")|>#fill in the blankcalculate(stat ="prop")#fill in the blank
Helpful Hint: Remember that you can use ? next to the function name to pull up the help file!
Calculate and visualize the distribution below.
visualize(null_dist)+shade_p_value(0.835, direction ="right")#fill in the blank
Warning in min(diff(unique_loc)): no non-missing arguments to min; returning
Inf
null_dist|>get_p_value(0.835, direction ="right")#fill in the blank
Warning: Please be cautious in reporting a p-value of 0. This result is an
approximation based on the number of `reps` chosen in the `generate()` step.
See `?get_p_value()` for more information.