AE 09: Data Import - Suggested Answers
Application exercise
Packages
We will use the following two packages in this application exercise.
- tidyverse: For data import, wrangling, and visualization.
- readxl: For importing data from Excel.
Warm Up
Recreate the Plot
- Let’s read in our data we created last time:
fisheries_summary <- read_csv("data/fisheries_summary.csv")Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): continent
dbl (3): min_aq_prop, max_aq_prop, mean_aq_prop
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.- Take a glimpse of your data set below.
# insert code here- Demo: Recreate the following plot using the data frame you have developed so far.

fisheries_summary |>
ggplot(
aes(x = mean_aq_prop, y = fct_reorder(continent,mean_aq_prop))
) +
geom_col() +
labs(
x = "",
y = "",
title = "Average share of aquaculture by continent",
subtitle = "out of total fisheries harvest, 2016",
caption = "caption goes here!"
) +
scale_x_continuous(labels = scales::percent) +
theme_classic() +
theme(axis.text.x = element_blank(), axis.ticks = element_blank())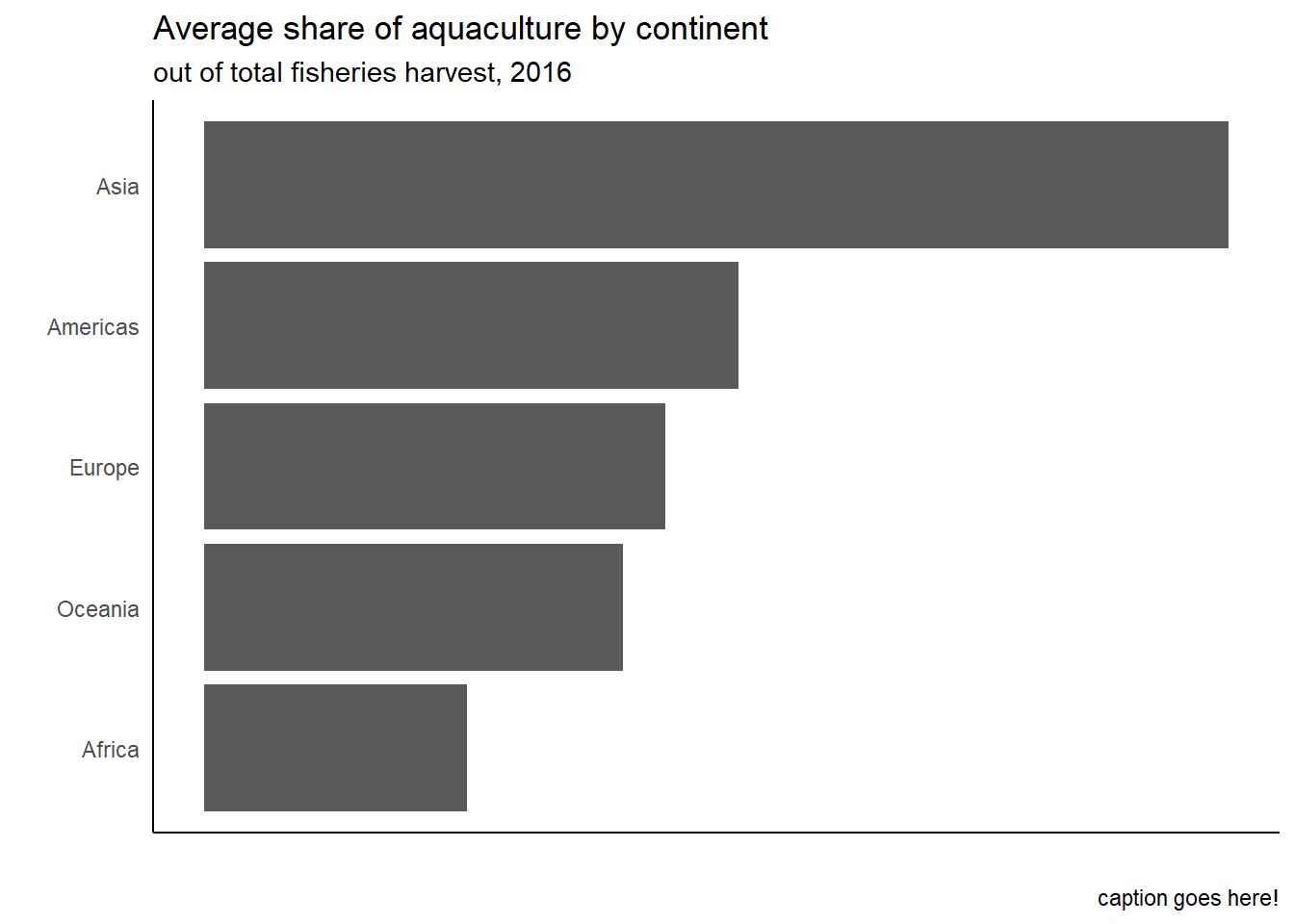
Data Import
Nobel winners
-
Demo: Load the data from the
datafolder and assign it tonobel. Confirm that this new object appears in your Environment tab.
#| label: data-import
nobel <- read_csv("data/nobel.csv")Rows: 935 Columns: 26
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (21): firstname, surname, category, affiliation, city, country, gender,...
dbl (3): id, year, share
date (2): born_date, died_date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.-
Your turn (4 minutes): Split the data into two – nobel laureates in STEM fields (
categoryshould be Physics, Medicine, Chemistry, or Economics) and nobel laureates in non-STEM fields. Name these two new objects appropriately. Remember: Use concise and evocative names. Confirm that these new objects appear in your Environment tab and that the sum of the number of observations in the two new data frames add to the number of observations in the original data frame.
-
Demo: Write out (export) the two new datasets you created into the
datafolder:
For this, we are going to use write_csv. The arguments of this function are: 1) the name of your data set in R; 2) the file path + name of your exported data set
Sales
Sales data are stored in an Excel file that looks like the following:

-
Demo: Read in the Excel file called
sales.xlsxfrom thedata/folder such that it looks like the following. Call it sales.

sales <- read_excel("data/sales.xlsx",
skip = 3,
col_names = c("id" , "n"))————————answer below———————————–
sales <- read_excel(
"data/sales.xlsx",
skip = 3,
col_names = c("id", "n")
)- Demo - Stretch goal: Manipulate the sales data such such that it looks like the following. Nzme the new data set sales2.
In this demo, we are going to learn to create and take advantage of logical variables. We are also going to be introduced to the function fill
- 2-min Think critically about the steps we need to take to create the new data below. You may also attempt to code through the steps.

sales |>
mutate(is_brand_name = str_detect(id, "Brand"),
brand = if_else(is_brand_name, id, NA)) |>
fill(brand) |>
filter(!is_brand_name) |>
select(brand, id , n)# A tibble: 7 × 3
brand id n
<chr> <chr> <chr>
1 Brand 1 1234 8
2 Brand 1 8721 2
3 Brand 1 1822 3
4 Brand 2 3333 1
5 Brand 2 2156 3
6 Brand 2 3987 6
7 Brand 2 3216 5 - Question: Why should we bother with writing code for reading the data in by skipping columns and assigning variable names as well as cleaning it up in multiple steps instead of opening the Excel file and editing the data in there to prepare it for a clean import?